Taiwan View簡介
發佈日期:2017-01-19
臺灣人體生物資料庫 幕僚長 吳佩怡
簡介臺灣人體生物資料庫
臺灣人體生物資料庫(Taiwan Biobank),歷經約十年可行性評估與先期規畫,在2012年為國內第一個正式通過衛福部核可的生物資料庫。從社區民眾開始,預計收集30萬筆人體生物資料,其中包含20萬位社區民眾與10萬名常見慢性疾病患者,希望能藉由蒐集自願參與之民眾的健康資料,進行長期追蹤與觀察,建立屬於臺灣本土的生物資料庫,供國內相關研究單位申請。從2012年開始至2016年底,Taiwan Biobank已經完成募集近8萬名社區民眾志願者,其中6千多人已完成了第一階段的追蹤,同時也展開與醫學中心合作,收集特定疾病患者。期望能透過生物醫學研究領域專家學者探討常見慢性疾病之基因與環境(包括生活習慣、飲食、行為、職業等)間交互作用,藉由未來各領域研究結果,瞭解國人常見疾病的致病因素,探討慢性疾病發生的可能原因。
自2003年全世界第一例全基體定序結果公佈後,全世界的生物醫學研究藉由基因資訊有大規模的進步,許多遺傳性疾病的發生導因於染色體上的某些特定區域或是基因發生變異,許多常見的複雜疾病是屬於多基因體變異交互作用造成,致病因子相當複雜,病因學探討亦較為困難。而且多數研究成果皆以歐美人口群為主,而各提供基因資訊的學術網站亦是以歐美人口群為主,若具有亞洲人口群基因資料則會以中國大陸與日本人為主要人口群,且樣本數規模往往不及歐美人口群,因此Taiwan Biobank希望透過30萬人臺灣人口群,建立臺灣特有的基因資訊。
全基因體定型與全基因體定型
Taiwan Biobank初期利用社區民眾之血液檢體,依據實驗技術成本考量採用全基因體定型(whole genome genotyping),採用美國Affymetrix公司所研發之技術平台,以Axiom Genome-Wide Array Plate晶片系統,內容涵蓋642,832基因位點,目前共完成16,036人,預計於2017年更新版本為20,000人。
然而採用全基因體定型具有實驗成本較低的優點,然而僅進行642,832基因位點定型,喪失了其他未進行基因型鑑定的區域可能對疾病造成影響的相關資訊,涵蓋率尚未滿足所有研究者之要求.,因此Taiwan Biobank亦進行全基因體定序(whole genome sequencing),結合全基因體掃描策略與全基因體定序建立完整基因體資料,未來可利用統計演算方法,推估基因定型的涵蓋率,將可增加基因定型資料的應用性。
1990年代的第一代定序方法,耗費了大量的金錢和時間才能完整的定序出一個人基因組,經過這20年多來的改良,發展出高通量及低成本的稱之為次世代定序(next-generation sequencing,NGS)技術,次世代定序策略是先解讀各個小片段的基因組序列,再運用資訊科技協助進行片段的接合,進而得到全基因體的定序。
全基因定序優點將會為國內學者帶來幾點助益:
- 建立臺灣自己的參考序列:目前研究學者所使用的基因參考序列,大部分都是來自於外國人種,而臺灣目前卻都還沒有擁有自己的參考序列,而透過臺灣人體生物資料庫的全基因體定序計畫,可以讓臺灣建立屬於臺灣自己的參考序列,讓國內的學者在進行臺灣本地的獨特研究時,不會因為參考序列上人種的關係進而錯估或損失了原本可能得到的線索。
- 為臺灣建立健康對照組的序列資訊:在進行分子流行病學中的病例對照研究法時,研究學者在收集了有興趣的疾病組的序列資訊進行研究時,必須還要花心思收集健康人組的核苷酸序列資訊。而透過臺灣人體生物資料庫收集的健康人檢體,並再加上健康人的全基因體的基因定序,可以幫助學者們不再重複資源收集健康人的資訊,不僅幫研究學者節省時間,也節省了大部分的經費。
- 作為基因填補法(genetic imputation)的模板,增加研究效益:建立台灣健康對照組全基因體序列資料庫,可作為基因填補法的模板。(1)在分子流行病學研究中若是研究沒有足夠經費及人力進行全基因型定序分析,只進行部分標誌基因型鑑定時,僅能獲得有限生物標記(biomarker)與疾病的關聯性。研究者可以利用台灣健康族群的全基因體定序作為模板,以基因填補法對於未有鑑定的等位基因預測其可能的基因型,此方式可以增加鑑定單一核苷酸基因多型性的密度,找出已經有關連性的疾病位點(disease locus) 其餘鄰近位點與疾病的關係,同時亦可確認挑選標誌單一核苷酸基因多型性的檢驗效能。(2)若進行多個分子流行病學研究數據的整合分析(meta analysis),也可以全基因體定序作為模板,將單一核苷酸基因多型性密度和個數不同研究以基因填補法填補為相同密度及尺度,進而獲得同個位點不同研究的結果,達到整合性分析結果。(3)若全基因體定序分析的樣本數過少時,可能會造成統計檢定力不足的問題,也可以利用基因填補法可以估計基因型,進而增加樣本量。
- 提供台灣健康族群低頻率變異(rare allele)分布情形:目前全基因體定型的設計,主要為尋找全體共通的遺傳變異(common variant),其單一核苷酸基因多型性的變異頻率(minor allele frequency,MAF)必須在健康族群大於5%才會納入晶片中,在演化上共通遺傳變異容易被保留下來,但是這些共通遺傳變異代表的不是致病基因變異(causal allele)而僅是生物標記(biomarker)。事實上,致病基因變異主要是以低頻率變異(rare variant)方式存在,這些低頻率變異較常出現在造成胺基酸改變的位置進而影響蛋白質功能,對於疾病造成重大的影響。然而低頻率變異常常被全基因體單一核苷酸基因多型性晶片忽略,而全基因體定序就可以彌補這個缺點,探測低頻率變異分布頻率,進而可以了解疾病的發生,台灣生物資料庫建立大型的全基因體定序,就可以做為研究者探討這些可能致病的低頻率變異在台灣健康族群分布的情形,以利後續研究。
Taiwan Biobank在全基因體定序同時選用Ion Proton與Illumina平台,有助於全面性的了解基因遺傳變異以及在基因層次上健康與疾病的關係,目前共完成997人,預計於2017年年中更新版本為1500人。
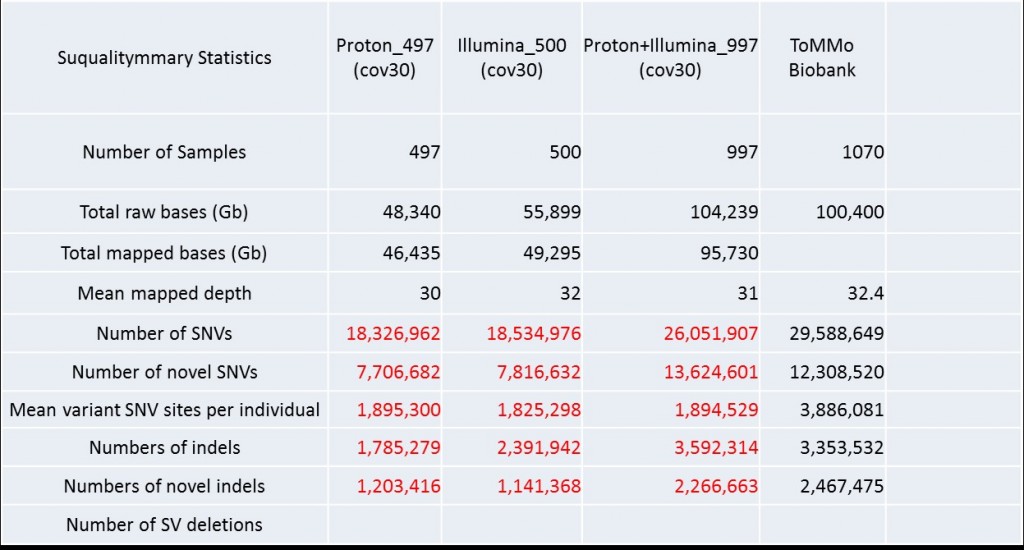
圖二以定序讀值平均倍數大於等於三十來看,共定序出兩千六百多萬個單核苷酸變異(Single Nucleotide Varants, SNVs),並且定序出近三百六十萬個Insertion與deletion(INDELs) 顯示Taiwan Biobank可提供有價值的全基因體定序資料給生物醫學界使用,這樣的結果與日本東北大學生物資料庫(ToMMo Biobank)差異性十分接近2。
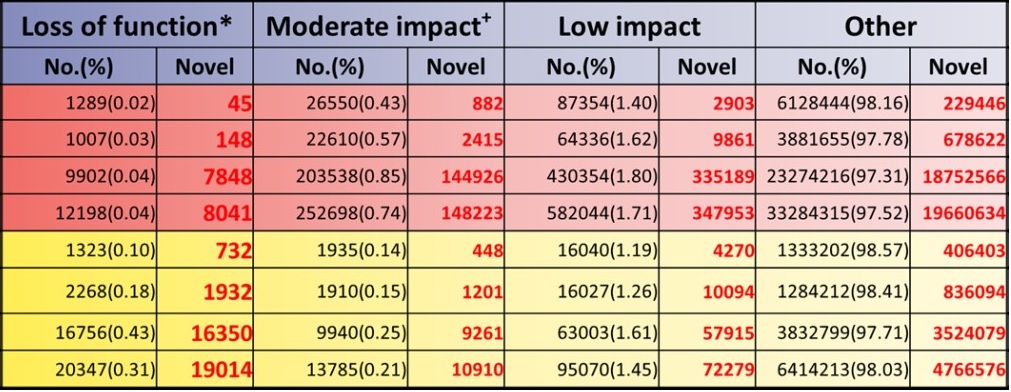
圖三顯示從核苷酸變異(包含SNV與INDELs)造成功能的影響進行分類,雖然這些核苷酸數目僅佔所有核苷酸的0.04%與0.31%,但是整體而言,從社區民眾血液中發現這些與生俱來造成功能影響的核苷酸變異,值得生物醫學界更進一步利用Taiwan Biobank資料探討健康狀況與基因的相關性,或是利用基因的變異探討未來罹患疾病的機率。
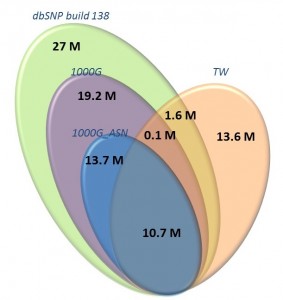
圖四的結果表示從臺灣人口群的單核苷酸變異中,有一千兩百多萬個單核苷酸變異在已知國際上資料庫可查詢到,但是仍然有一千三百多萬個單核苷酸變異在國際上的資料庫中無法查詢,此結果再一次驗證臺灣有建立自己的基因資訊的必要性,利用屬於臺灣人口群獨特的基因變異,將可能尋找出臺灣獨特的致病原因。
簡介Taiwan View
Taiwan Biobank將全基因體定型與全基因體定型的Summary data放在網站上,提供有興趣查詢(Taiwan View https://taiwanview.twbiobank.org.tw/index)與下載。
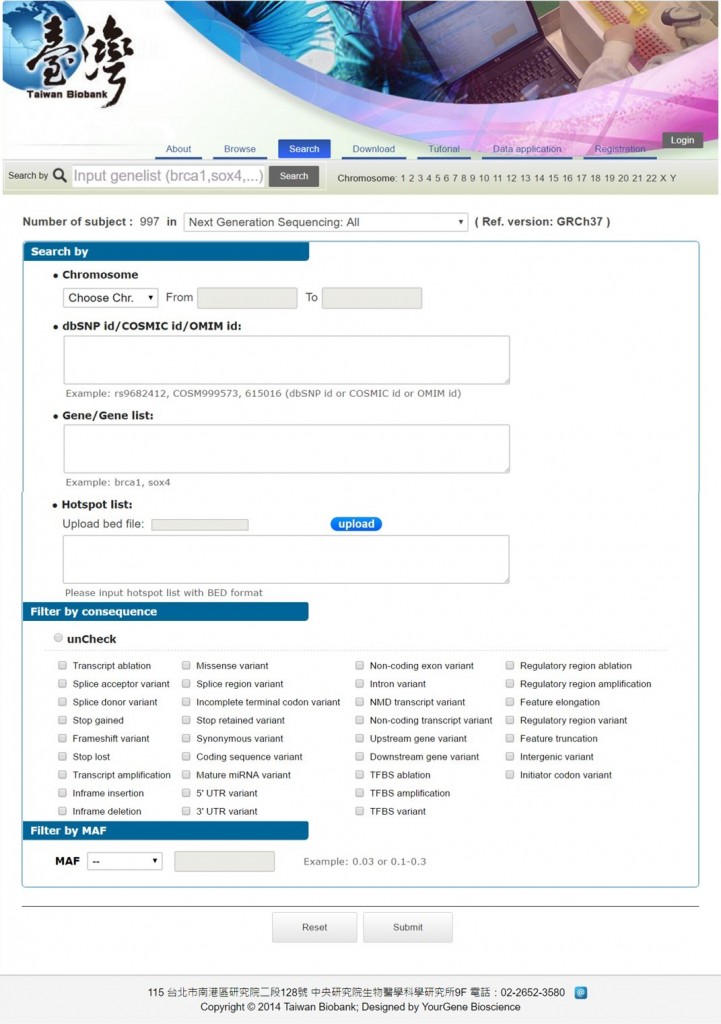
查詢結果顯示臺灣人口群基因型分布數量與頻率,該並藉由網頁上註解之連結,將Ensembl的核苷酸資訊彙整,將更進一步瞭解核苷酸參考值、變異值相關等等資訊。此外可以藉由資料申請,提供individual data作為基因醫學研究的基礎。
基因資訊未來規劃
隨著Taiwan Biobank收集的社區民眾與疾病患者陸續增加,也將建立全基因體甲基化與HLA資訊,預計2017年中更新與Taiwan View。此外針對部分疾病患者的組織檢體,將規劃特定基因的深度定序,於協助生物醫學研究領域專家學者以臺灣特有的基因資料,找出對抗疾病的發生,進展和治療上的線索,促進國人未來的健康。
參考資料
- Chen CH. Population structure of Han Chinese in the modern Taiwanese population based on 10,000 participants in the Taiwan Biobank project. Hum Mol Genet. 2016 Oct 18.
- Nagasaki M. Rare variant discovery by deep whole-genome sequencing of 1,070 Japanese individuals. Nat Commun. 2015 Aug 21.
簡介臺灣人體生物資料庫
臺灣人體生物資料庫(Taiwan Biobank),歷經約十年可行性評估與先期規畫,在2012年為國內第一個正式通過衛福部核可的生物資料庫。從社區民眾開始,預計收集30萬筆人體生物資料,其中包含20萬位社區民眾與10萬名常見慢性疾病患者,希望能藉由蒐集自願參與之民眾的健康資料,進行長期追蹤與觀察,建立屬於臺灣本土的生物資料庫,供國內相關研究單位申請。從2012年開始至2016年底,Taiwan Biobank已經完成募集近8萬名社區民眾志願者,其中6千多人已完成了第一階段的追蹤,同時也展開與醫學中心合作,收集特定疾病患者。期望能透過生物醫學研究領域專家學者探討常見慢性疾病之基因與環境(包括生活習慣、飲食、行為、職業等)間交互作用,藉由未來各領域研究結果,瞭解國人常見疾病的致病因素,探討慢性疾病發生的可能原因。
自2003年全世界第一例全基體定序結果公佈後,全世界的生物醫學研究藉由基因資訊有大規模的進步,許多遺傳性疾病的發生導因於染色體上的某些特定區域或是基因發生變異,許多常見的複雜疾病是屬於多基因體變異交互作用造成,致病因子相當複雜,病因學探討亦較為困難。而且多數研究成果皆以歐美人口群為主,而各提供基因資訊的學術網站亦是以歐美人口群為主,若具有亞洲人口群基因資料則會以中國大陸與日本人為主要人口群,且樣本數規模往往不及歐美人口群,因此Taiwan Biobank希望透過30萬人臺灣人口群,建立臺灣特有的基因資訊。
全基因體定型與全基因體定型
Taiwan Biobank初期利用社區民眾之血液檢體,依據實驗技術成本考量採用全基因體定型(whole genome genotyping),採用美國Affymetrix公司所研發之技術平台,以Axiom Genome-Wide Array Plate晶片系統,內容涵蓋642,832基因位點,目前共完成16,036人,預計於2017年更新版本為20,000人。
然而採用全基因體定型具有實驗成本較低的優點,然而僅進行642,832基因位點定型,喪失了其他未進行基因型鑑定的區域可能對疾病造成影響的相關資訊,涵蓋率尚未滿足所有研究者之要求.,因此Taiwan Biobank亦進行全基因體定序(whole genome sequencing),結合全基因體掃描策略與全基因體定序建立完整基因體資料,未來可利用統計演算方法,推估基因定型的涵蓋率,將可增加基因定型資料的應用性。
1990年代的第一代定序方法,耗費了大量的金錢和時間才能完整的定序出一個人基因組,經過這20年多來的改良,發展出高通量及低成本的稱之為次世代定序(next-generation sequencing,NGS)技術,次世代定序策略是先解讀各個小片段的基因組序列,再運用資訊科技協助進行片段的接合,進而得到全基因體的定序。
全基因定序優點將會為國內學者帶來幾點助益:
- 建立臺灣自己的參考序列:目前研究學者所使用的基因參考序列,大部分都是來自於外國人種,而臺灣目前卻都還沒有擁有自己的參考序列,而透過臺灣人體生物資料庫的全基因體定序計畫,可以讓臺灣建立屬於臺灣自己的參考序列,讓國內的學者在進行臺灣本地的獨特研究時,不會因為參考序列上人種的關係進而錯估或損失了原本可能得到的線索。
- 為臺灣建立健康對照組的序列資訊:在進行分子流行病學中的病例對照研究法時,研究學者在收集了有興趣的疾病組的序列資訊進行研究時,必須還要花心思收集健康人組的核苷酸序列資訊。而透過臺灣人體生物資料庫收集的健康人檢體,並再加上健康人的全基因體的基因定序,可以幫助學者們不再重複資源收集健康人的資訊,不僅幫研究學者節省時間,也節省了大部分的經費。
- 作為基因填補法(genetic imputation)的模板,增加研究效益:建立台灣健康對照組全基因體序列資料庫,可作為基因填補法的模板。(1)在分子流行病學研究中若是研究沒有足夠經費及人力進行全基因型定序分析,只進行部分標誌基因型鑑定時,僅能獲得有限生物標記(biomarker)與疾病的關聯性。研究者可以利用台灣健康族群的全基因體定序作為模板,以基因填補法對於未有鑑定的等位基因預測其可能的基因型,此方式可以增加鑑定單一核苷酸基因多型性的密度,找出已經有關連性的疾病位點(disease locus) 其餘鄰近位點與疾病的關係,同時亦可確認挑選標誌單一核苷酸基因多型性的檢驗效能。(2)若進行多個分子流行病學研究數據的整合分析(meta analysis),也可以全基因體定序作為模板,將單一核苷酸基因多型性密度和個數不同研究以基因填補法填補為相同密度及尺度,進而獲得同個位點不同研究的結果,達到整合性分析結果。(3)若全基因體定序分析的樣本數過少時,可能會造成統計檢定力不足的問題,也可以利用基因填補法可以估計基因型,進而增加樣本量。
- 提供台灣健康族群低頻率變異(rare allele)分布情形:目前全基因體定型的設計,主要為尋找全體共通的遺傳變異(common variant),其單一核苷酸基因多型性的變異頻率(minor allele frequency,MAF)必須在健康族群大於5%才會納入晶片中,在演化上共通遺傳變異容易被保留下來,但是這些共通遺傳變異代表的不是致病基因變異(causal allele)而僅是生物標記(biomarker)。事實上,致病基因變異主要是以低頻率變異(rare variant)方式存在,這些低頻率變異較常出現在造成胺基酸改變的位置進而影響蛋白質功能,對於疾病造成重大的影響。然而低頻率變異常常被全基因體單一核苷酸基因多型性晶片忽略,而全基因體定序就可以彌補這個缺點,探測低頻率變異分布頻率,進而可以了解疾病的發生,台灣生物資料庫建立大型的全基因體定序,就可以做為研究者探討這些可能致病的低頻率變異在台灣健康族群分布的情形,以利後續研究。
Taiwan Biobank在全基因體定序同時選用Ion Proton與Illumina平台,有助於全面性的了解基因遺傳變異以及在基因層次上健康與疾病的關係,目前共完成997人,預計於2017年年中更新版本為1500人。
圖二以定序讀值平均倍數大於等於三十來看,共定序出兩千六百多萬個單核苷酸變異(Single Nucleotide Varants, SNVs),並且定序出近三百六十萬個Insertion與deletion(INDELs) 顯示Taiwan Biobank可提供有價值的全基因體定序資料給生物醫學界使用,這樣的結果與日本東北大學生物資料庫(ToMMo Biobank)差異性十分接近2。
圖三顯示從核苷酸變異(包含SNV與INDELs)造成功能的影響進行分類,雖然這些核苷酸數目僅佔所有核苷酸的0.04%與0.31%,但是整體而言,從社區民眾血液中發現這些與生俱來造成功能影響的核苷酸變異,值得生物醫學界更進一步利用Taiwan Biobank資料探討健康狀況與基因的相關性,或是利用基因的變異探討未來罹患疾病的機率。
圖四的結果表示從臺灣人口群的單核苷酸變異中,有一千兩百多萬個單核苷酸變異在已知國際上資料庫可查詢到,但是仍然有一千三百多萬個單核苷酸變異在國際上的資料庫中無法查詢,此結果再一次驗證臺灣有建立自己的基因資訊的必要性,利用屬於臺灣人口群獨特的基因變異,將可能尋找出臺灣獨特的致病原因。
簡介Taiwan View
Taiwan Biobank將全基因體定型與全基因體定型的Summary data放在網站上,提供有興趣查詢(Taiwan View https://taiwanview.twbiobank.org.tw/index)與下載。
查詢結果顯示臺灣人口群基因型分布數量與頻率,該並藉由網頁上註解之連結,將Ensembl的核苷酸資訊彙整,將更進一步瞭解核苷酸參考值、變異值相關等等資訊。此外可以藉由資料申請,提供individual data作為基因醫學研究的基礎。
基因資訊未來規劃
隨著Taiwan Biobank收集的社區民眾與疾病患者陸續增加,也將建立全基因體甲基化與HLA資訊,預計2017年中更新與Taiwan View。此外針對部分疾病患者的組織檢體,將規劃特定基因的深度定序,於協助生物醫學研究領域專家學者以臺灣特有的基因資料,找出對抗疾病的發生,進展和治療上的線索,促進國人未來的健康。
參考資料
- Chen CH. Population structure of Han Chinese in the modern Taiwanese population based on 10,000 participants in the Taiwan Biobank project. Hum Mol Genet. 2016 Oct 18.
- Nagasaki M. Rare variant discovery by deep whole-genome sequencing of 1,070 Japanese individuals. Nat Commun. 2015 Aug 21.